Supervision Tree
Have you try turn it off and on again ?
In one of my previous post (Let it crash) we talked about how good Erlang and Elixir are at fault tolerance, and how they could restart an app when it crashes, so it wouldn’t cause any impact in our customers. We also mentioned that all of this was handled by the supervision tree. So now is time to talk a bit about the supervision tree.
In Elixir and Erlang, we have what are known as Supervisors. The responsibility of a supervisor is to check that a process (worker) is alive and restart it if it’s dead. A process is The basic unit of Erlang/Elixir concurrency model. Every single piece of code from your application is going to run in a process.
Supervisors can check for processes and other supervisors too. That way we can build a hierarchical process structure of supervisors and processes called supervision tree. Supervision trees are a nice way to structure fault-tolerant applications, to isolate errors when they appear. The main idea of a supervision tree is to have a way to keep our software going in case of errors by just restarting the faulty processes.
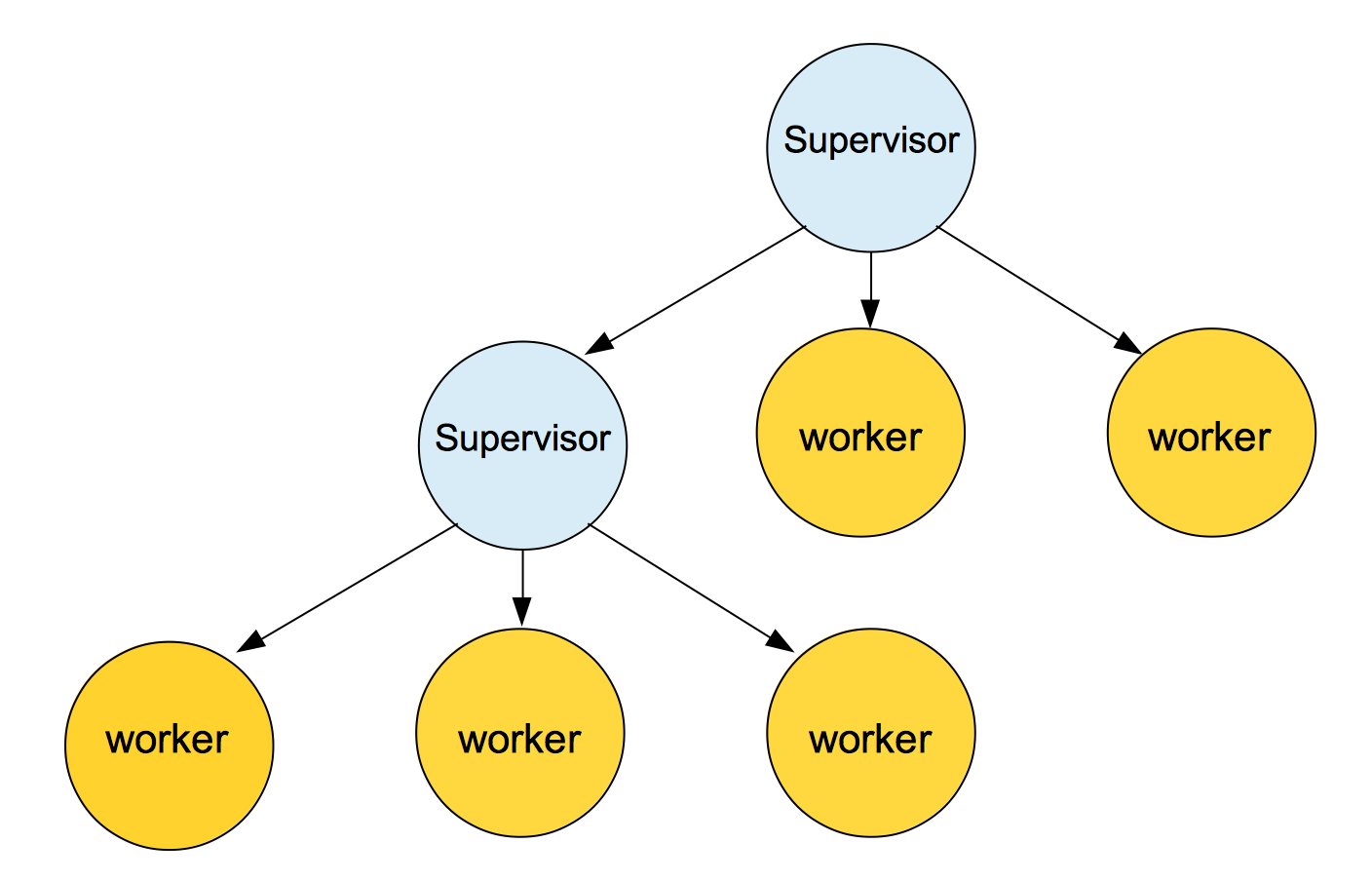
If a worker dies, the supervisor can restart the dead worker and its children if it has any. The way that the process will get restarted, it will depend on the strategy selected. Supervisors supports different supervision strategies :
-
one for one: - if a child process terminates, only that process is restarted.
-
one for all: - if a child process terminates, all other child processes are terminated and then all child processes (including the terminated one) are restarted.
-
rest for one: - if a child process terminates, the “rest” of the child processes, i.e., the child processes after the terminated one in start order, are terminated. Then the terminated child process and the rest of the child processes are restarted.
-
simple one for one: - similar to :one_for_one but suits better when dynamically attaching children. This strategy requires the supervisor specification to contain only one child.
Once a process has died the supervisor will try to restart it again, if it keeps dying it will keep trying until it reaches the max number of restarting in a period of time. This is a parameter option that will be passed to the supervisor when it is created, if a supervisor reaches that number it will gives up and terminates. The main reason for that is that you don’t want your Supervisor to infinitely restart its children when something is genuinely wrong in your code or application.
Supervisors have a very simple job and they are very old, they were first implemented more than 20 years ago in Erlang, so they have gone through all kind of testing and are very solid and stable process, as a consequence they are very unlikely to crash. The beautiful outcome of this is, when something inevitably goes wrong in one of the leaves or the branches of the tree, the problem is isolated and easily recovered without disturbing the rest of the application.
The following code is been extracted from a real backend application and represent the supervision tree of a backend system.
defmodule ItemsApi do
use Application
def start(type, args) do
import Supervisor.Spec, warn: false
children = [
supervisor(ItemsApi.Endpoint, []),
supervisor(ItemsApi.Repo, []),
supervisor(ItemsApi.Mailer, []),
]
opts = [strategy: :one_for_one, name: ItemsApi.Supervisor]
Supervisor.start_link(children, opts)
end
endThis backend system is composed of an API that has a few end points, a db to store some items, that get posted through the API and a mail system that will send emails to certain users when some events happens. If we represent the previous code in a supervision tree map, we will have something like:
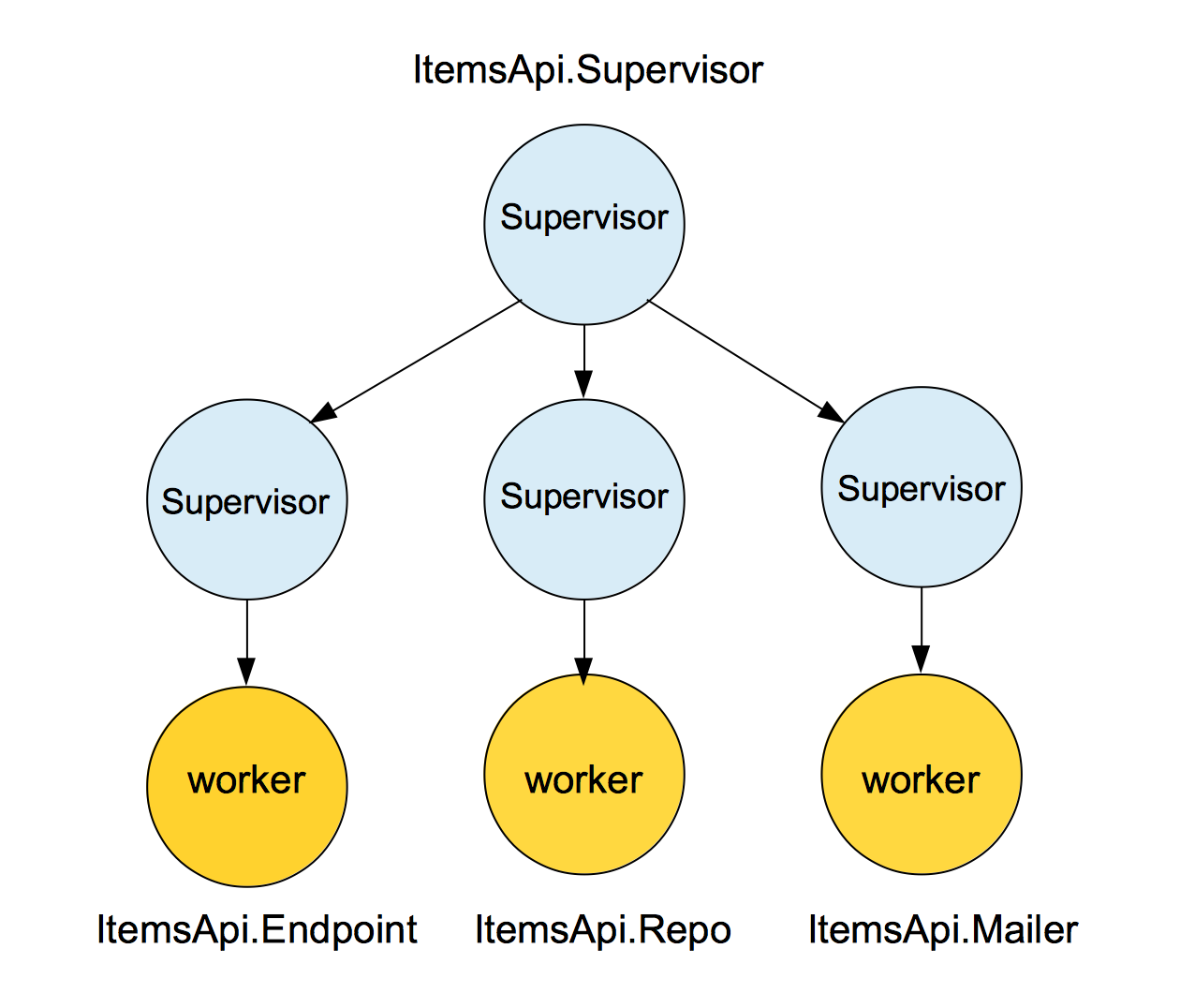
When the application start, it will call the start function which will create three supervisors children:
children = [
supervisor(ItemsApi.Endpoint, []),
supervisor(ItemsApi.Repo, []),
supervisor(ItemsApi.Mailer, []),
]The first supervisor will check the worker in charge of keeping the endpoint up and running, the second one will check the Ecto repository worker and the third one will check that the mail system is running. At the same time the main supervisor(ItemsApi.Supervisor) is supervising all the other supervisors. All of those processes are completely independent from each other and if one of them crashes, it won’t affect any of the other two:
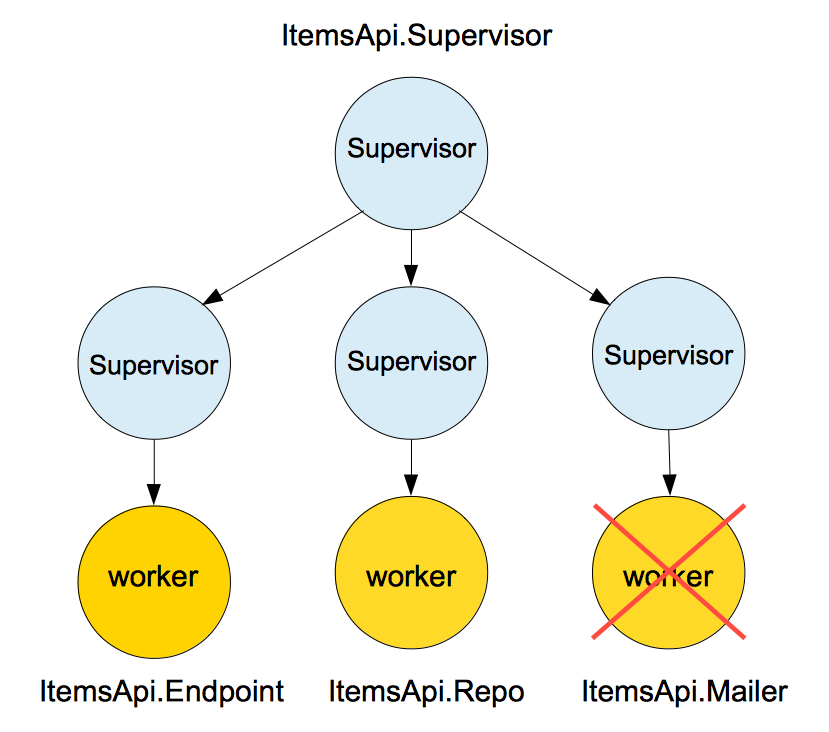
As we can see in the picture, the mailer process has crashed, but the fact that the mailer process has crashed and we can’t send emails anymore, it shouldn’t affect people making calls to the API to fetch or save data. They are functionally independent from each other, so errors in one place shouldn’t affect the other. Right after the crash, the mailer supervisor will try to restart the mail worker again, if it doesn’t succeed, it will keep trying until it reaches the max number of restarting in a period of time.
opts = [strategy: :one_for_one, name: ItemsApi.Supervisor]
Supervisor.start_link(children, opts)In this last bit of code is where we start the main supervisor, the Gen server supervisor that will supervise all the children supervisors with the strategy selected. If any of the children, then the main supervisor will restart the dead ones. But who supervise the main supervisor ? what happen if the main supervisor die ? Well if the main supervisor die, then we will be in trouble at this point, but as we mentioned before you will rarely see a supervisor dying.
This a fairly basic introduction the the world of supervisors and the supervision tree, if you want to know more about it, I definitely recommend you to have a look at learn you some Erlang - supervisors
Final thoughts
Fault tolerant systems like Erlang and Elixir will monitor your system silently in the background and they will react to failures, restarting a process if they crash. The beautiful outcome of this is that if your system crashes for unknown reasons, your customers won’t notice unless there is something genuinely wrong with your code, and the process keep crashing over and over again until Erlang give up. On top of that even if there is something genuinely wrong with a particular bit of code, Elixir and Erlang will isolate the problem so the only part of your system affected will be the one related to that particular process. All of this is handle by the supervision tree, and the best part of it is that it all comes for free with Erlang and Elixir.
References